DEEP LEARNING TECHNOLOGY
Marpai is a technology company bringing the most advanced AI into employer health plans to save lives,
improve lives and radically reduce healthcare spending
Industry’s First Purpose-built Deep Learning Prediction Platform
Marpai’s deep learning algorithms represent the greatest health state prediction available today in employer health plans. Marpai can predict potential near-term health events related to chronic illness (like Type 2 Diabetes) and major procedures (like knee surgery) and intervene early to prevent costly claims.
Powered by a deep neural network brain that mimics the logic and learning of the human brain, Marpai’s deep learning platform anticipates and predicts potential health events with unmatched speed and accuracy.
What is Deep Learning?
Deep learning is the most advanced subset of AI, leveraging deep neural networks that take inspiration from how the human brain works. It is artificial intelligence method that imitates the way the human brain works in the sense of processing data and creating patterns for use in decision making. It utilizes a hierarchical level of artificial neural networks to carry out the learning process involved in machine learning. The artificial neural networks are built like the human brain, with neuron nodes connected like an interconnected web.
As more data is fed into the neural network, it becomes better at intuitively understanding the meaning of new data. This allows it to predict and prevent increasingly advanced threats such as health risks. It does not require a (human) expert to help it understand the significance of new features.
The advantage of deep learning over other forms of machine learning is the end-to-end processing of data. These three factors contribute to deep learning’s greater level of accuracy.
Deep Learning
Innovation Hub
Marpai’s R&D center is Marpai Labs, a deep learning innovation hub in Tel Aviv. A team of top data scientists work with health experts and Marpai’s $50MM+ tech platform to pioneer advanced technologies for health plans. Staffed with deep learning scientists, Marpai Labs is a magnet for top talent and a hotbed of tech innovation.

“Marpai and Mphasis share the vision of using technology to disrupt and overhaul the healthcare industry as we know it today. I applaud what Marpai is setting out to do by applying AI to create monumental change–for the industry, employer groups, providers and members. Their insights are market leading and it is a privilege to call them a partner.”
Sally Else, President, Mphasis Javelina
Key Differences Between Machine Learning and Deep Learning
Machine Learning systems rely on feature engineering which is limited to the knowledge of the expert who has to handcraft the features for detection. Machine learning-based solutions are still producing low detection rates and high false-positive rates. With Deep Learning, the algorithm analyzes all the raw data in a file, and is not limited by an expert’s capabilities. This represents a quantum leap in computer science. For future health states, this enables a more advanced level of prediction; with higher detection rates, lower false-positive rates and the ability to detect health risks effectively in zero-time.
| Machine Learning | Deep Learning | |
|---|---|---|
| Domain Expert | Featuring Engineering & Extraction Requires a human domain expert to define and engineer features for conducting classification. |
Autonomous Looks at all the raw data in a fully autonomous manner. |
| Extent of Analysis | A Fraction of Available Data is Analyzed By converting the data into small vector of features, e.g. statistical correlations, it is inevitably ignoring most of the data. |
Processes 100% of Available Raw Data One of the major strengths of deep learning is the massive number of characteristics from the raw data that is processes to obtain a decision. |
| Scalability | Limited in its Scalability Although machine learning can scale across diverse datasets, there is an information threshold, which if reached, additional data training doesn’t provide any further accuracy. |
Improves with More Exposure The deep neural network continually improves as the training data set constantly grows, it is the only method that benefits from scaling into hundreds of millions of training samples. |
Building the Neural Network
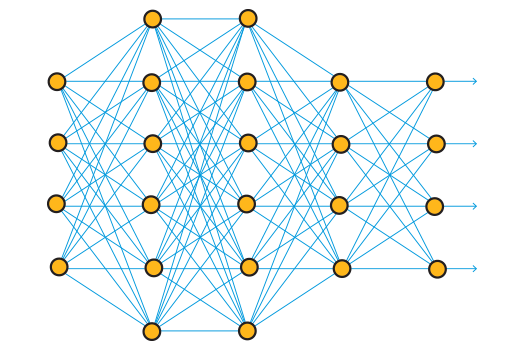
Traditional Neural Network

Deep Neural Network
~90% size reduction during training
Data scientists prepare data samples to train the “brain” or deep neural network. During the “training” phase, the deep neural network is exposed to all the available raw data in a file from which it learns to instinctively identify health risks. This process takes place within 24-48 hours. Once the network has reached the prediction stage, it can quickly and efficiently predict where a health risk exists or not. The input agnostic algorithm can apply this knowledge to any sort of file. Next, the brain is compressed into a lightweight agent where Terabytes of insights are turned into Megabytes of instincts. The agent is always working to detect health risks.
Our Data Power

We are creating a robust deep learning infrastructure that will allow us to analyze nearly any type of data. More importantly, this infrastructure is expected to have the capability to automatically train on multiple data types at once and obtain unified predictions from that data. Specifically, we expect our deep learning capabilities to be used for the following data types:
Structured data: This includes any form of data that results in a tabular database. Examples of such data include laboratory tests, claims data, and payment details to healthcare providers. Our deep learning models for structured data, which rely on fully connected neural networks, allow us to automatically train on any such structured databases and incorporate those insights into predictive models.
Images: While traditional image processing requires cumbersome development for each specific use case, deep learning-based models can directly operate on any image data without having to go through a preprocessing feature extraction phase. We are developing a series of deep learning models based on convolutional neural networks that could be extended to process medical images, including radiology imaging such as MRIs, CT scans, x-rays, ultrasounds, and PET scans, as well as other types of medical images, such as those used in dermatology, pathology, and ophthalmology.
Text: Traditionally, analyzing text data requires lengthy natural language processing, or “NLP.” Recent breakthroughs in deep learning, especially the advent of transformer networks (e.g., BERT), allow for the end-to-end training of language models, which results in significantly higher accuracy than previous NLP methods. Our infrastructure includes support for these deep learning-based language models, allowing us to automatically process textual data as well. A prime example of textual medical data is the plain text description of doctors’ notes, which include information about symptoms, diagnosis, and treatment. Even though some of this data, such as disease codes, appears in structured databases as well, the textual data contains a large amount of information that does not appear elsewhere.
Multi-type data: Deep learning can also be applied to multiple data sources and data types. During the first stage, the relevant deep learning models are applied to each data type (e.g., CNN for images, Transformers for text, and so on), and then, during the second stage, the processed information from those various data sources is fed into a secondary deep learning model that provides unified predictions. This is one of the major advantages of deep learning over traditional AI, as it allows the incorporation of multiple big data sources into a single unified prediction model. This approach far exceeds the accuracy rate achieved by traditional methods.
Data fusion: With deep learning, we have the ability to study different data types together, such as data in the form of images (e.g., CT scans) with data in tabular form (e.g., figures from healthcare claims). Putting these different data types together is referred to as data fusion.